Agnostics (ICLR 2026)
Learning to Code in Any Programming Language via Reinforcement with a Universal Learning Environment
Agnostics (ICLR 2026) is a collaboration with Yangtian Zi, Zixuan Wu, Tejas Oberoi, Carolyn Jane Anderson, Joydeep Biswas, and Arjun Guha.
LLMs excel at programming languages like Python and JavaScript, yet stumble on low-resource languages essential to science and engineering. Post-training the models is a bottleneck: every new language seems to require new data, new tests, and more reinforcement learning infrastructure.
We show how to turn an existing dataset of coding problems into a reinforcement learning environment which can be adapted to any programming language. Our approach turns Qwen 3 4B and 8B into SOTA ≤16B models for low-resource programming languages, rivaling much larger models, including their 32B sibling. And when we trained Qwen 3 4B on very low-resource programming languages, the comparison wasn’t even fair. (We’re comparing them on our multi-language version of LiveCodeBench, which we’re releasing together with the report!)
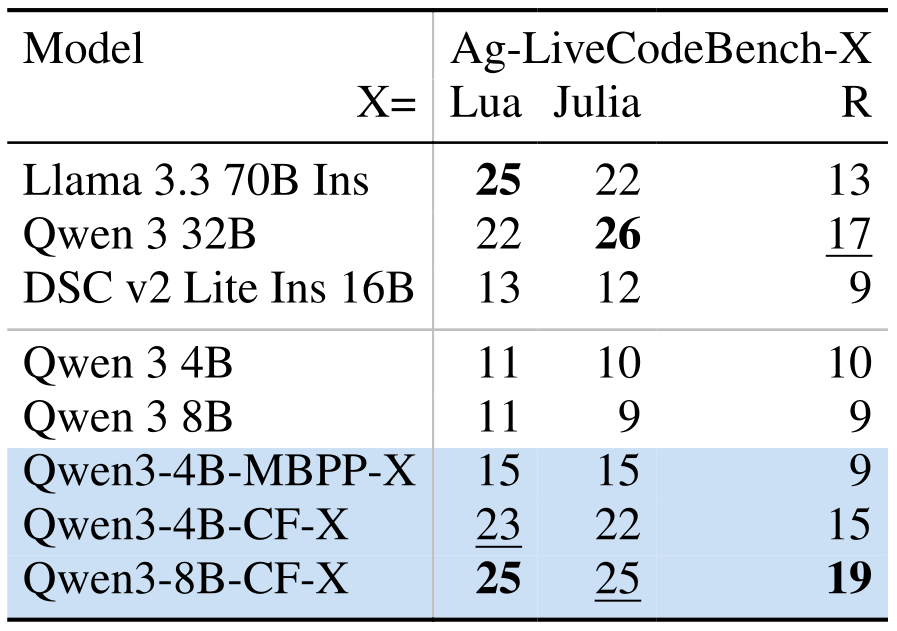 | 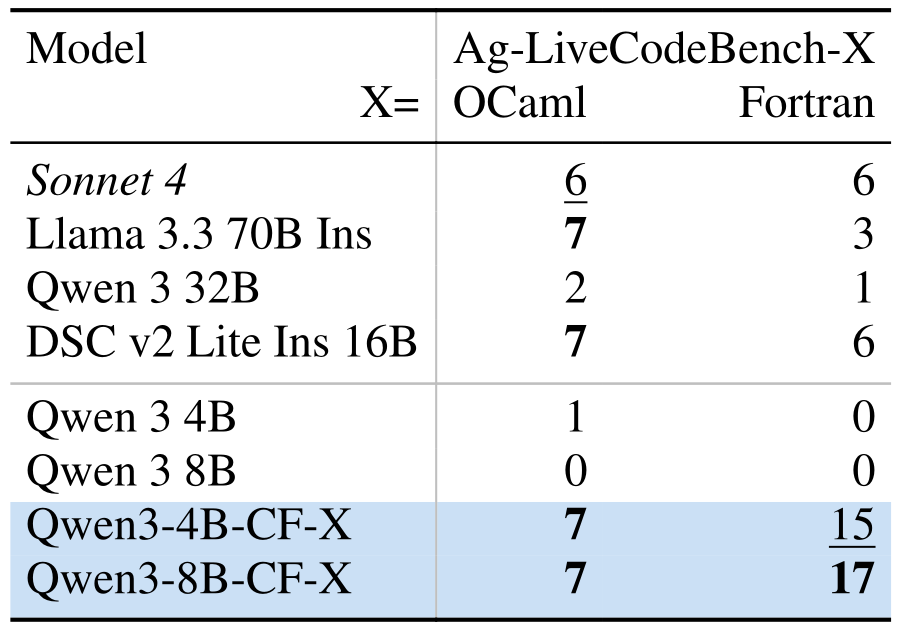 |
|---|
Links
The ICLR review & paper is available here.
Our training framework and code for running the Ag-LiveCodeBench-X benchmark are available here.
Our datasets and models are available here, and our code execution containers are available here. Our wandb data can be found here.
The ArXiv report is available here.
Brief overview
Our key novel idea is to judge code only by its externally observable behavior (e.g., I/O). Some datasets are already in such a format, many others can be rewritten to it. We can write a universal verifier for such problems, which lets us teach a model any programming language. One universal verifier + a tiny per-language YAML file = reinforcement learning that works everywhere.
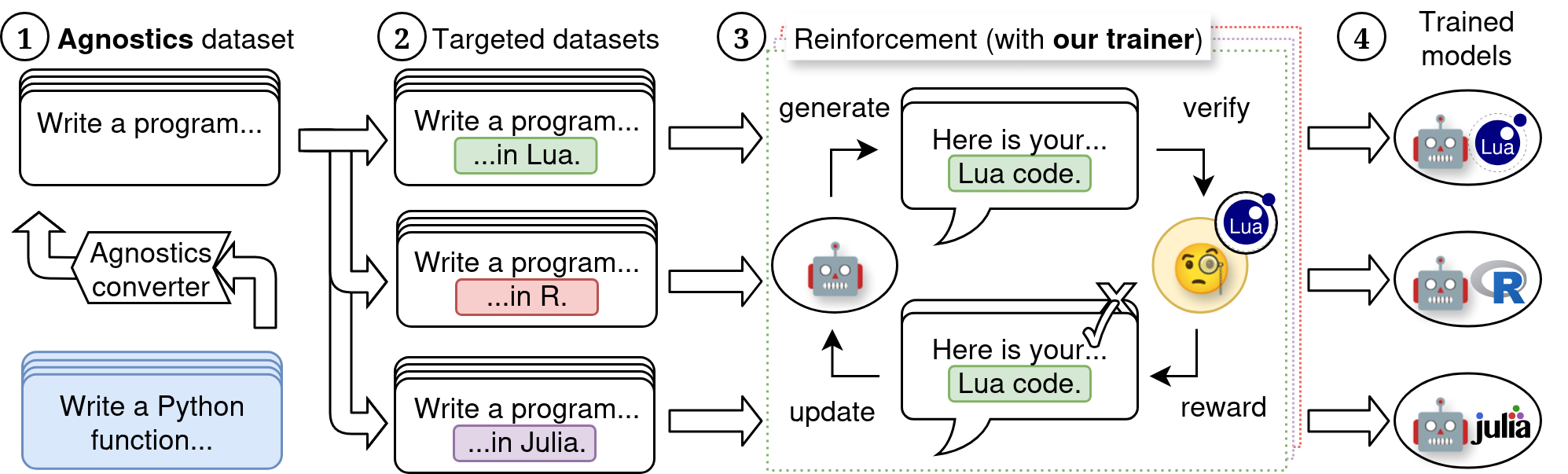
(1) We use an LLM to reformulate language-specific datasets into our standard language-agnostic format. (2) We generate prompts and a configured verifier targeting a particular language, with a small (often 4-line!) configuration. (3) We apply reinforcement learning with verified rewards (RLVR) using a robust, language-agnostic execution sandbox that we develop. (4) The result is a model specialized to the target language.
Our approach particularly excels at finetuning models for low-resource languages, since it does not rely on language-specific high-quality datasets.
An analysis of the generated programs shows that the trained models make fewer syntax and API mistakes.
The models have learned the simpler rules of the language,
which also reveals the algorithmic mistakes they make.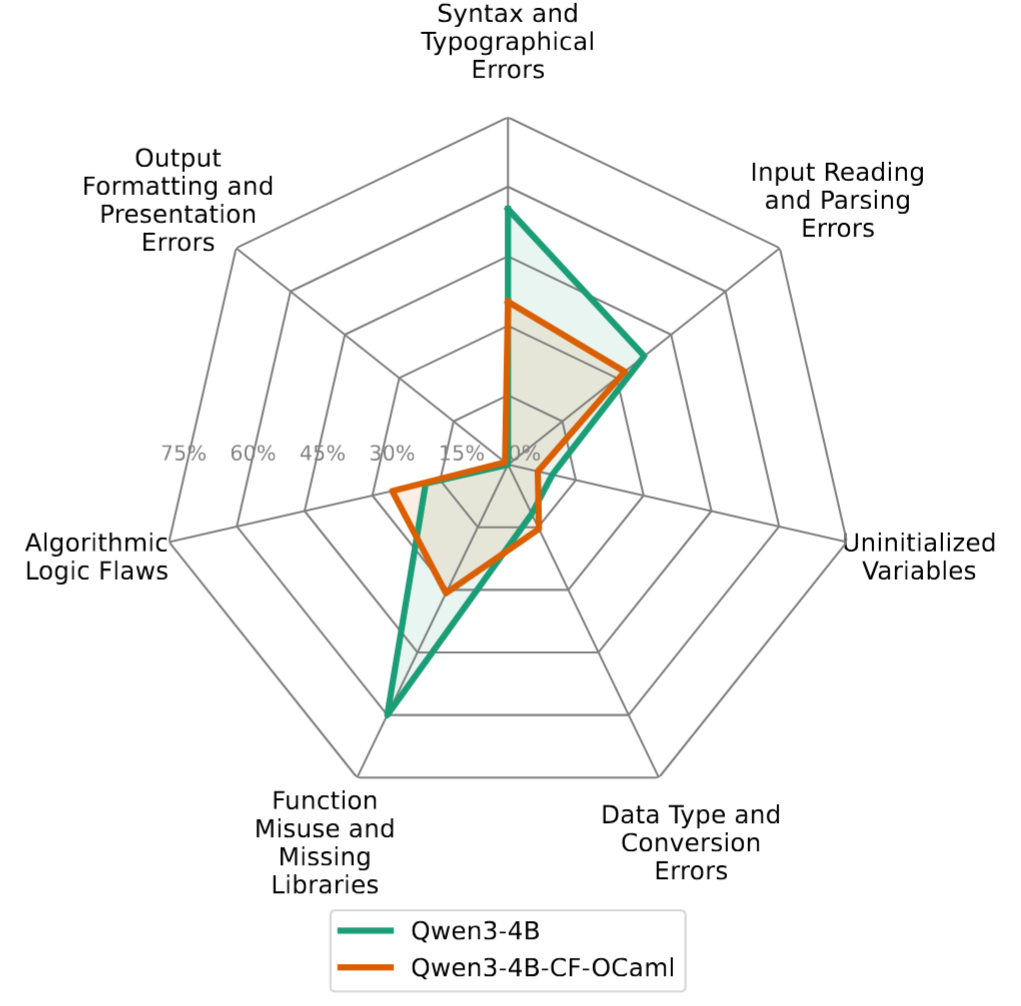
Find out more by reading the paper here!
Alex Boruch-Gruszecki
Postdoc
Interested in LLM-based code synthesis informed by a deep understanding of programming languages.